FAQ
General
What is SQLMesh?
SQLMesh is an open source data transformation framework that brings the best practices of DevOps to data teams. It enables data engineers, scientists, and analysts to efficiently run and deploy data transformations written in SQL or Python.
It is created and maintained by Tobiko Data, a company founded by data leaders from Airbnb, Apple, and Netflix.
Check out the quickstart guide to see it in action.
What is SQLMesh used for?
SQLMesh is used to manage and execute data transformations - the process of converting raw data into a form useful for making business decisions.
What problems does SQLMesh solve?
Problem: organizing, maintaining, and changing data transformation code in SQL or Python
Solutions:
- Identify dependencies among data transformation models and determine the order in which they should run
- Run data audits and unit tests to prevent unintended side effects from code changes
- Implement best practices from the DevOps paradigm, such as development environments and continuous integration/continuous development (CI/CD)
- Execute transformations written in one SQL dialect on an engine/database that runs a different SQL dialect (SQL transpilation)
Problem: understanding a complex set of data transformations
Solutions:
- Determine and display the flow of data through data transformation models
- Trace which columns in a table contribute to a column in another table (column-level lineage)
Problem: inefficient, unnecessarily expensive data transformations
Solutions:
- Understand the impacts of a code change on the codebase and underlying data tables without running the code
- Efficiently deploy code changes by only running the transformations impacted by the changes
- Safely promote transformations executed in a development environment to production so computations aren’t needlessly re-executed
Problem: complex business requirements and data transformations
Solutions:
- Easily and safely implement incremental data loading
- Perform complex data transformations or operations with Python models (e.g., machine learning models, geocoding)
...and more!
What is semantic understanding of SQL?
Semantic understanding is the result of analyzing SQL code to determine what it does at a granular level. SQLMesh uses the free, open-source Python library SQLGlot to parse the SQL code and build the semantic understanding.
Semantic understanding allows SQLMesh to do things like transpilation (executing one SQL dialect on an engine running another dialect) and preventing incremental loading queries from duplicating data.
Does SQLMesh work like Terraform?
SQLMesh was inspired by Terraform, but its commands are not equivalent.
Terraform's "plan" approach compares a local configuration to a remote configuration and determines what actions are needed to synchronize the two. Similarly, SQLMesh compares the state of local project files (such as SQL models) to an environment and determines the actions needed to synchronize them.
However, the commands to create and apply a plan are different. In Terraform, the "plan" command generates a plan and saves it to file. The "apply" command reads a plan file and applies it.
In SQLMesh, the sqlmesh plan command generates a plan, runs any unit tests, and prompts the user to apply the plan. There is no "apply" command in SQLMesh.
Getting Started
How do I install SQLMesh?
SQLMesh is a Python library. After ensuring you have an appropriate Python runtime, install it with pip.
How do I use SQLMesh?
SQLMesh has three interfaces: command line, Jupyter or Databricks notebook, and graphical user interface.
The quickstart guide demonstrates an example project in each of the interfaces.
Usage
Why does SQLMesh create schemas?
SQLMesh creates schemas for two reasons:
- SQLMesh stores state/metadata information about a project in the
sqlmeshschema. This schema is created in the project's default gateway, or you can specify a different location. - SQLMesh uses Virtual Data Environments to prevent duplicative computation whenever possible, and stores environment-specific objects in separate schemas by default.
How Virtual Data Environments work:
Virtual Data Environments work by maintaining a virtual layer of views that users interact with when building models and a physical layer of tables that stores the actual data.
Each SQLMesh environment consists of a collection of views. When changes are promoted from one environment to another (e.g., dev to prod), SQLMesh determines whether the data in an underlying physical table is equivalent between the environments. If it is, SQLMesh simply modifies the environment's view to pull from a different underlying physical table instead of redoing the computations that have already occurred.
SQLMesh creates schemas for both the physical and virtual layers. The physical layer is stored in a schema named sqlmesh__[project name]. For example, the quickstart example's physical layer is stored in the sqlmesh__sqlmesh_example schema.
The virtual layers are stored in one schema per environment. All SQLMesh projects contain a prod environment by default - its virtual layer is stored in the project name schema (e.g., sqlmesh_example for the quickstart). Other environments' virtual layers are stored in schemas of the form [project name]__[environment name]. For example, the quickstart example dev environment's virtual layer is in the sqlmesh_example__dev schema.
The SQLMesh janitor automatically deletes unused environment schemas. It determines whether an environment schema should be deleted based on the elapsed time since the sqlmesh plan [environment name] command was successfully executed for the environment. If that time is greater than the environment time to live (default value of 1 week), the environment schema is deleted.
SQLMesh's default behavior is appropriate for most deployments, but you can override where SQLMesh creates physical tables and views with schema configuration options.
What's the difference between a test and an audit?
A SQLMesh test is analogous to a "unit test" in software engineering. It tests code based on known inputs and outputs. In SQLMesh, the inputs and outputs are specified in a YAML file, and SQLMesh automatically runs them when sqlmesh plan is executed.
Writing YAML is annoying and error-prone, so SQLMesh's create_test command allows you to automatically generate YAML test files based on queries of existing data tables.
A SQLMesh audit validates that transformed data meet some criteria. For example, an audit might verify that a column contains no NULL values or has no duplicated values. SQLMesh automatically runs audits when a sqlmesh plan is executed and the plan is applied or when sqlmesh run is executed.
When the sqlmesh plan command is executed, SQLMesh tests run before any model's code is executed. A SQLMesh model's audits run after the model's code is executed to validate the data output by the model.
How does a model know when to run?
A SQLMesh model determines when to run based on its cron parameter and how much time has elapsed since its previous run.
Models are not aware of upstream data updates and do not run based on what has happened in an upstream data source.
What is the model cron parameter?
SQLMesh does not fully refresh models every time a project is run. Instead, you specify how frequently each model should run with its cron parameter (defaults to daily).
When you execute sqlmesh run, SQLMesh compares each model's cron value to its record of when the model was last run. If enough time has elapsed it will run the model, otherwise it does nothing.
For example, consider a model whose cron is daily. The first time you execute sqlmesh run today the model will run. If you execute sqlmesh run again, SQLMesh will detect that the model has already run today and will not re-run the model.
What's the difference between sqlmesh plan and sqlmesh run?
During project development, there are two things in play: the current state of your project files and the existing states of each environment you have.
SQLMesh’s plan command is the primary tool for understanding the effects of changes you make to your project. If your project files have changed or are different from the state of an environment, you execute sqlmesh plan [environment name] to synchronize the environment's state with your project files. sqlmesh plan will generate a summary of the actions needed to implement the changes, automatically run unit tests, and prompt you to apply the plan and implement the changes.
If your project files have not changed, you execute sqlmesh run to run your project's models and audits.
sqlmesh run does not use models, macros, or audits from your local project files. Everything it executes is based on the model, macro, and audit versions currently promoted in the target environment. Those versions are stored in the metadata SQLMesh captures about the state of your environment.
A sensible approach to executing sqlmesh run is to use Linux’s cron tool to execute sqlmesh run on a cadence at least as frequent as your briefest SQLMesh model cron parameter. For example, if your most frequent model’s cron is hour, your cron tool should execute sqlmesh run at least every hour.
What are start date and end date for?
SQLMesh uses the "intervals" approach to determine the date ranges that should be included in an incremental by time model query. It divides time into disjoint intervals and tracks which intervals have ever been processed.
Start date plays two separate roles in SQLMesh. In an incremental model configuration, the start parameter tells SQLMesh the first date that should be included in the model's set of time intervals.
Start date and end date also play a role as parameters for SQLMesh commands like plan and run. In this context, start and end tell SQLMesh that only certain time intervals should be included when executing the command. For example, you might process only a few intervals to iterate quickly during development before processing all of time when deploying to production.
How do I reprocess data I already transformed?
Sometimes you need to reprocess data that has already been loaded and transformed. In SQLMesh, you do that with restatement plans.
Specify the plan command's --restate-model option and the model name(s) you want to reprocess. Applying the plan will reprocess those models and all models downstream from them. You can use the --start and --end options to limit the reprocessing to a specific date range.
How do I reuse an existing table instead of creating a new one?
Sometimes a table is too large to completely rebuild for a breaking change, so you need to reuse the existing table. This is done with forward-only plans. Create one by adding the --forward-only option to the plan command: sqlmesh plan [environment name] --forward-only.
When a forward-only plan is applied to the prod environment, none of the plan's changed models will have new physical tables created for them. Instead, physical tables from previous model versions are reused. All changes made as part of a forward-only plan automatically get a forward-only category assigned to them - they can't be mixed together with regular breaking/non-breaking changes.
You can retroactively apply the forward-only plan's changes to existing data in the production environment with plan's --effective-from option.
How can I force a model to run now?
Ensure that the model's allow_partials attribute is set to true and execute the run command with the --ignore-cron option: sqlmesh run --ignore-cron.
See the documentation for allow_partials to understand the rationale behind this.
Databases/Engines
What databases/engines does SQLMesh work with?
See this page for the list of currently supported engines.
Scheduling
How do I run SQLMesh models on a schedule?
You can run SQLMesh models using the built-in scheduler or using Tobiko Cloud
Both approaches use each model's cron parameter to determine when the model should run - see the question about cron above for more information.
The built-in scheduler works by executing the command sqlmesh run. A sensible approach to running on your project on a schedule is to use Linux’s cron tool to execute sqlmesh run on a cadence at least as frequent as your briefest SQLMesh model cron parameter. For example, if your most frequent model’s cron is hour, the cron tool should execute sqlmesh run at least every hour.
How do I use SQLMesh with Airflow?
Tobiko Cloud offers first-class support for Airflow - learn more here
How do I use SQLMesh with Dagster?
Tobiko Cloud offers first-class support for Dagster - learn more here
Warnings and Errors
Why did I get the warning 'Query cannot be optimized due to missing schema(s) for model(s): [...]'?
SQLMesh uses its knowledge of table schema (column names and data types) to optimize model queries and create column-level lineage. SQLMesh does not have schema knowledge for data sources outside the project and will generate this warning when a model selects from one.
You can resolve this by creating an external model for each external data source. The sqlmesh create_external_models command captures schema information for external data sources and stores them in the project's schema.yml file. You can create the file manually instead, if desired.
Why did I get the error 'Table "xxx" must match the schema's nesting level: 3'?
SQLMesh throws this error when a model’s name does not include a schema. Model names must be of the form schema.table or catalog.schema.table.
How is this different from dbt?
Terminology differences?
- dbt “materializations” are analogous to model
kindsin SQLMesh - dbt seeds are a model kind in SQLMesh
- dbt’s “tests” are called
auditsin SQLMesh because they are auditing the contents of data that already exists. SQLMeshtestsare equivalent to “unit tests” in software engineering - they evaluate the correctness of code based on known inputs and outputs. dbt buildis analogous tosqlmesh run
Workflow differences?
dbt workflow
- Configure your project and set up one database connection target for each environment you will use during development
- Create, configure, and modify models, seeds, tests, and other project components
- Execute
dbt build(or its constituent partsdbt run,dbt seed, etc.) to evaluate and test the project components - Execute
dbt build(or its constituent partsdbt run,dbt seed, etc.) on a schedule to ingest and transform new data
SQLMesh workflow
- Configure your project and set up a project database (using DuckDB locally or a database connection)
- Create, configure, and modify models, audits, tests, and other project components
- Execute
sqlmesh plan [environment name]to:- Generate a summary of the differences between your project files and the environment and whether each change is
breaking. Theplanincludes a list of the actions needed to implement the changes and automatically runs the project's unittests. - Optionally apply the plan to implement the actions and run the project's
audits.
- Generate a summary of the differences between your project files and the environment and whether each change is
- Execute
sqlmesh runon a schedule to ingest and transform new data
Differences in running models?
dbt projects are executed with the commands dbt run (models only) or dbt build (models, tests, snapshots).
In SQLMesh, the execution depends on whether the project’s contents have been modified since the last execution:
- If they have been modified, the
sqlmesh plancommand both:- Generates a summary of the actions that will occur to implement the code changes and
- Prompts the user to "apply" the plan and execute those actions.
-
If they have not been modified, the
sqlmesh runcommand will evaluate the project models and run the audits. SQLMesh determines which project models should be executed based on theircronconfiguration parameter.For example, if a model’s
cronisdailythensqlmesh runwill only execute the model once per day. If you issuesqlmesh runthe first time on a day the model will execute; if you issuesqlmesh runagain nothing will happen because the model shouldn’t be executed again until tomorrow.
Differences in state management?
dbt
By default, dbt runs/builds are independent and have no knowledge of previous runs/builds. This knowledge is called “state” (as in “the state of things”).
dbt has the ability to store/maintain state with the state selector method and the defer feature. dbt stores state information in artifacts like the manifest JSON file and reads the files at runtime.
The dbt documentation “Caveats to state comparison” page comments on those features: “The state: selection method is a powerful feature, with a lot of underlying complexity.”
SQLMesh
SQLMesh always maintains state about the project structure, contents, and past runs. State information enables powerful SQLMesh features like virtual data environments and easy incremental loads.
State information is stored by default - you do not need to take any action to maintain or to use it when executing models. As the dbt caveats page says, state information is powerful but complex. SQLMesh handles that complexity for you so you don't need to worry about the underlying mechanics.
SQLMesh stores state information in database tables. By default, it stores this information in the same database/connection where your project models run. You can specify a different database/connection if you would prefer to store state information somewhere else. We recommend using a separate connection for storing state in production deployments.
SQLMesh adds information to the state tables via transactions, and some databases like BigQuery are not optimized to execute transactions. Changing the state connection to another database like PostgreSQL can alleviate performance issues you may encounter due to state transactions.
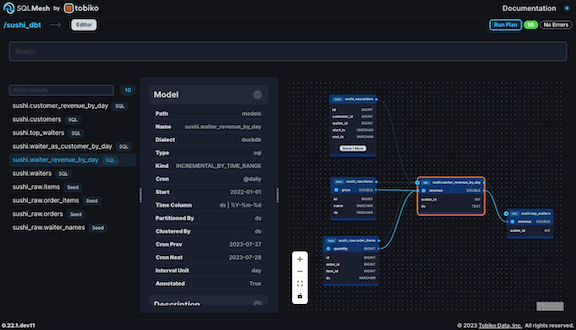
How do I get column-level lineage for my dbt project?
SQLMesh can run dbt projects with its dbt adapter. After configuring the dbt project to work with SQLMesh, you can view the column-level lineage in the SQLMesh browser UI:
Do I have to run Python models in my SQL engine?
No! SQLMesh executes Python models wherever SQLMesh is running, and there are no restrictions on what they can do as long as they return a Pandas or Spark DataFrame instance.
If the data is too large to fit in memory, the model can process it in batches or execute the transformations on an external Spark cluster.
How do incremental models determine which dates to ingest?
dbt uses the "most recent record" approach to determine which dates should be included in an incremental load. It works by querying the existing data for the most recent date it contains, then ingesting all records after that date from the source system in a single query.
SQLMesh uses the "intervals" approach instead. It divides time into disjoint intervals based on a model's cron parameter then records which intervals have ever been processed. It ingests source records from only unprocessed intervals. The intervals approach enables features like loading in batches.
How do I run an append only model in SQLMesh?
SQLMesh does not support append-only models as implemented in dbt. You can achieve a similar outcome by defining a time column and using an incremental by time range model or specifying a unique key and using an incremental by unique key model.
Company
How does Tobiko Data make money?
- Tobiko Cloud: learn more here
- Enterprise Github Actions CI/CD App (in development)
- Advanced version of open source CI/CD bot
- Providing hands-on support for companies' SQLMesh projects