Incremental by time guide
SQLMesh models are classified by kind. One powerful model kind is "incremental by time range" - this guide describes how these models work and demonstrates how to use them.
See the models guide to learn more about working with models in general or the model kinds concepts page for an overview of the different model kinds.
Load the right data
The incremental by time approach to data loading is motivated by efficiency. It is based on the principle of only loading a given data row one time.
Model kinds such as VIEW or FULL reload the entirety of the source system's data every time they run. In some cases, reloading all the data is not feasible. In other cases, it is an inefficient use of time and computational resources - both of which equate to money your business could spend on something else.
Incremental by time models only load new data, drastically decreasing the computational resources required for each model run.
Counting time
Incremental by time models work by first identifying the date range for which data should be read from the source table.
One approach to determining the date range bases it on the most recent record timestamp observed in the data. That approach is simple to implement, but it makes three assumptions: the table already exists, there are no temporal gaps in the data, and that the query is able to run in a single pass.
SQLMesh takes a different approach by using time intervals.
Calculating intervals
The first step to using time intervals is to create the set of all intervals based on the model's start datetime and interval unit. The start datetime specifies when time "begins" for the model, and interval unit specifies how finely time should be divided.
For example, consider a model with a start datetime of 12am two days ago that we are working with today at 12pm. This is illustrated in Figure 1:
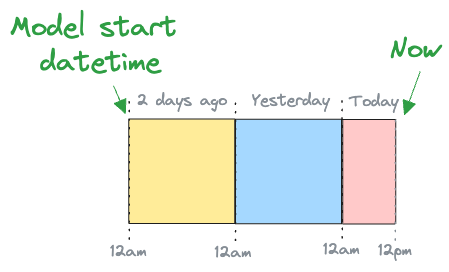
Figure 1: Illustration of model with start datetime of 12am two days ago that we are working with today at 12pm
If the model's interval unit was 1 day, the model's set of intervals would have 3 entries:
- 1 for two days ago
- 1 for yesterday
- 1 for today
Today's interval is not yet complete because it's 12pm right now. This is illustrated in the top panel of Figure 2:
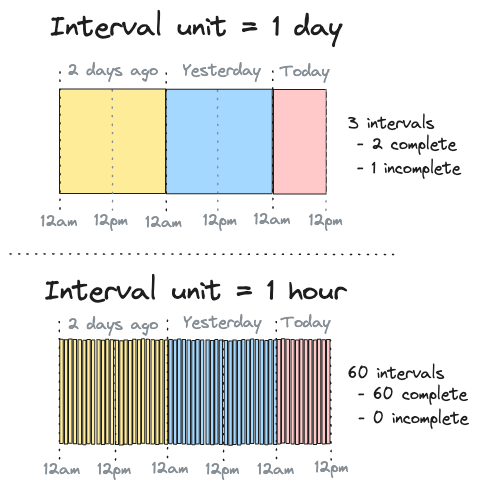
Figure 2: Illustration of counting intervals over a 60 hour period with interval units of 1 day and 1 hour
If the model's interval unit was 1 hour instead, its set of time intervals would have 60 entries:
- 24 for each hour of two days ago
- 24 for each hour of yesterday
- 12 for each hour today from 12am to 12pm
All intervals are complete because it is 12pm (so the 11am interval has ended). This is illustrated in the bottom panel of Figure 2.
When we first execute and backfill the bottom model as part of a sqlmesh plan today at 12pm, SQLMesh calculates its set of 60 time intervals and records that all 60 of them were backfilled. It retains this information in the SQLMesh state tables for future use.
If we sqlmesh run the model tomorrow at 12pm, SQLMesh calculates the set of all intervals as:
- 24 for two days ago
- 24 for yesterday
- 24 for today
- 12 for tomorrow 12am to 12pm
This gives a total of 84 intervals.
It compares this set of 84 to the stored set of 60 that we already backfilled to identify the 24 un-processed intervals from 12pm yesterday to 12pm today. It then processes only those 24 intervals during today's run.
Running run
SQLMesh has two different commands for processing data. If any model has been changed, sqlmesh plan is used to apply the change to data in a specific environment. If no models have changed, sqlmesh run is used to execute the project's models.
Data accumulation rates and freshness requirements may differ across models. If sqlmesh run ran every model whenever the command was executed, all models would be held to the same freshness requirements as the most stringent model. This is inefficient and wastes computational resources (and money).
Instead, you specify the cron parameter for each model. sqlmesh run uses each model's cron to determine whether that model should be executed in a given run.
For example, if your most frequent model's cron is hourly, you need to execute the sqlmesh run command at least hourly (with a tool like Linux's cron). That model will run once every hour, but another model with a cron of daily will only run once per day when 24 hours have elapsed since its previous run.
Scheduling computations
By default, SQLMesh processes all intervals that have elapsed since a model's previous run in a single job. If a model's source data is large, you may want to break the computations up into smaller jobs - this is done with the model configuration's batch_size parameter.
When batch_size is specified, the total number of intervals to process is divided into batches of size batch_size, and one job is executed for each batch.
Model time
Incremental by time models require specification of a time column in their configuration. In addition, their model SQL queries should specify a WHERE clause that filters the data on a time range.
This example shows an incremental by time model that could be added to the SQLMesh quickstart project:
The model configuration specifies that the column model_time_column represents the time stamp for each row, and the model query contains a WHERE clause that uses the time column to filter the data.
The WHERE clause uses the SQLMesh predefined macro variables @start_ds and @end_ds to specify the date range. SQLMesh automatically substitutes in the correct dates based on which intervals are being processed in a job.
Important
The time_column should be in the UTC time zone to ensure correct interaction with SQLMesh's scheduler and predefined macro variables.
In addition to the query WHERE clause, SQLMesh prevents data leakage by automatically wrapping the query in another time-filtering WHERE clause using the time column in the model's configuration.
This raises a question: if SQLMesh automatically adds a time filtering WHERE clause, why do you need to include one in the query? Because the two filters play different roles:
- The model query
WHEREclause filters the data read into the model - The SQLMesh wrapper
WHEREclause filters the data output by the model
The model query ensures that only the necessary data is processed by the model, so no resources are wasted. It also adds flexibility - if an upstream model uses a different time column than the model itself, that column can be used in addition to (or in place of) the model's time column in the query WHERE clause.
The SQLMesh wrapper clause prevents data leakage by ensuring the model does not return records outside the time range. This is a safety mechanism that guards against improperly specified queries.
For some queries, the two filters are functionally duplicative, but for others they are not. There is no way for SQLMesh to determine whether they are duplicative in any given instance, so the model query should always include a time-filtering WHERE clause.
Forward-only models
Every time a model is modified, SQLMesh classifies the change as "breaking" or "non-breaking."
Breaking changes may invalidate data for downstream models, so a new physical table is created and fully refreshed for the changed model and all models downstream of it. Non-breaking changes only affect the changed model, so only its physical table is refreshed.
Sometimes a model's data may be so large that it is not feasible to rebuild either its own or its downstream models' physical tables. In those situations a third type of change, "forward only," can be used. The name reflects that the change is only applied "going forward" in time.
Specifying forward-only
Forward-only changes can be specified in two ways. First, a model can be configured as forward-only such that all changes to them are automatically classified as forward-only. This guarantees that the model's physical table will never be fully refreshed.
This example configures the model in the previous example to be forward only:
Alternatively, all the changes contained in a specific plan can be classified as forward-only with a flag: sqlmesh plan --forward-only. A subsequent plan that did not include the forward-only flag would fully refresh the model's physical table. Learn more about forward-only plans here.
Schema changes
When SQLMesh processes forward-only changes to incremental models, it compares the model's new schema with the existing physical table schema to detect potential data loss or compatibility issues. SQLMesh categorizes schema changes into two types:
Destructive changes
Some model changes destroy existing data in a table. Examples include:
- Dropping a column from the model
- Renaming a column
- Modifying a column data type in a ways that could cause data loss
Whether a specific change is destructive may differ across SQL engines based on their schema evolution capabilities.
Additive changes
Additive changes are any changes to the table's columns that aren't categorized as destructive. A simple example would be adding a column to a table but another would be changing a column data type to a type that is compatible (ex: INT -> STRING).
SQLMesh performs schema change detection at plan time based on the model definition. If SQLMesh cannot resolve all of a model's column data types at plan time, the check is performed again at run time based on the physical tables underlying the model.
Changes to forward-only models
SQLMesh provides two configuration settings to control how schema changes are handled:
on_destructive_change- Controls behavior for destructive schema changeson_additive_change- Controls behavior for additive schema changes
Configuration options
Both properties support four values:
error(default foron_destructive_change): Stop execution and raise an errorwarn: Log a warning but proceed with the changeallow(default foron_additive_change): Silently proceed with the changeignore: Skip the schema change check entirely for this change type
Ignore is Dangerous
ignore is dangerous since it can result in error or data loss. It likely should never be used but could be useful as an "escape-hatch" or a way to workaround unexpected behavior.
Destructive change handling
The on_destructive_change configuration setting determines what happens when SQLMesh detects a destructive change. By default, SQLMesh will error so no data is lost.
This example configures a model to silently allow destructive changes:
Additive change handling
The on_additive_change configuration setting determines what happens when SQLMesh detects an additive change like adding new columns. By default, SQLMesh allows these changes since they don't destroy existing data.
This example configures a model to raise an error for additive changes (useful for strict schema control):
Combining both settings
You can configure both settings together to have fine-grained control over schema evolution:
Model defaults
Default values for both on_destructive_change and on_additive_change can be set for all incremental models in the model defaults configuration.
Common use cases
Here are some common patterns for configuring schema change handling:
Strict schema control - Prevent any schema changes:
Permissive development model - Allow all schema changes:
Production safety - Allow safe changes, warn about risky ones:
Changes in forward-only plans
The SQLMesh plan --forward-only option treats all the plan's model changes as forward-only. When this option is specified, SQLMesh will check all modified incremental models for both destructive and additive schema changes, not just models configured with forward_only true.
SQLMesh determines what to do for each model based on this setting hierarchy:
- For destructive changes: the model's
on_destructive_changevalue (if present), theon_destructive_changemodel defaults value (if present), and the SQLMesh global default oferror - For additive changes: the model's
on_additive_changevalue (if present), theon_additive_changemodel defaults value (if present), and the SQLMesh global default ofallow
If you want to temporarily allow destructive changes to models that don't allow them, use the plan command's --allow-destructive-model selector to specify which models. Similarly, if you want to temporarily allow additive changes to models configured with on_additive_change=error, use the --allow-additive-model selector. Learn more about model selectors here.